




Phục chế Di sản Văn hóa Kỹ thuật số
Phục chế Di sản Văn hóa Kỹ thuật số
Phân đoạn và chú thích dữ liệu di sản 3D đa tỷ lệ
Bởi Arnadi Murtiyoso • Ngày 15 tháng 4 năm 2021
(Tiến sĩ Vũ Văn Chất sưu tầm và biên soạn)
Cho dù là bản vẽ 2D hay đám mây điểm 3D, di sản văn hóa kỹ thuật số đang trở thành tiêu chuẩn trong tài liệu di sản ngày nay. Tuy nhiên, dữ liệu kỹ thuật số thô vẫn yêu cầu ghi nhãn thủ công để thêm thông tin hữu hình vào dữ liệu hình học nghiêm ngặt. Bài viết này trình bày một cách tiếp cận thuật toán để giải cấu trúc một cách có hệ thống và chú thích ngữ nghĩa dữ liệu di sản 3D thành các phần tử riêng biệt. Phương pháp được phát triển giúp giảm bớt các nhiệm vụ gắn nhãn và cung cấp dữ liệu đào tạo cho những phát triển trong tương lai trong phân khúc dựa trên trí tuệ nhân tạo.
Tầm quan trọng của việc lập hồ sơ di sản thích hợp tiếp tục tăng lên khi đối mặt với những thiệt hại tiềm tàng bởi các mối đe dọa từ thiên nhiên và con người. Trong những thập kỷ gần đây, sự phát triển của địa tin học đã làm cho việc quét 3D trở nên dễ dàng và khả thi hơn đối với các tác nhân bảo tồn. Đã đạt được những bước tiến lớn trong lĩnh vực đo quang và quét laze, hai trong số những hình thức tạo dữ liệu 3D chiếm ưu thế nhất trong lĩnh vực tư liệu di sản. Để hỗ trợ quản lý di sản, các hệ thống như GIS 3D và mô hình thông tin xây dựng di sản (HBIM) cũng đã được phát triển.
Giải quyết hai điểm nghẽn chính
Điểm nghẽn chính trong quá trình tạo ra một hệ thống quản lý di sản thống nhất với nhiều bên liên quan là việc số hóa và dán nhãn thủ công các yếu tố trên đám mây điểm. Điều này là cần thiết để hiểu đúng cảnh và do đó thực hiện phân tích có ý nghĩa thông qua khung 3D GIS hoặc HBIM. Mặc dù cũng có thể quan sát thấy những tiến bộ đáng kể trong việc sử dụng trí tuệ nhân tạo trong việc thực hiện các nhiệm vụ này, nhưng điều này cũng gặp phải một nút thắt cổ chai dưới dạng tính sẵn có của dữ liệu đào tạo. Hơn nữa, trong lĩnh vực di sản, sự đa dạng của các phong cách kiến trúc trên khắp thế giới tạo ra một lớp bổ sung cho vấn đề này. Phương pháp được phát triển cố gắng giải quyết hai điểm nghẽn này cùng một lúc. Thứ nhất, việc sử dụng các phương pháp tiếp cận dựa trên thuật toán hoặc quy tắc tạo ra các tập dữ liệu được gắn nhãn đủ nhanh và chính xác cho một số nghiên cứu trường hợp đơn giản hơn. Thứ hai, kết quả sau đó có thể được sử dụng lại cho dữ liệu đào tạo như một loại phương pháp khởi động trong bất kỳ phương pháp học máy nào trong tương lai - hoặc thực sự là dựa trên học sâu -.
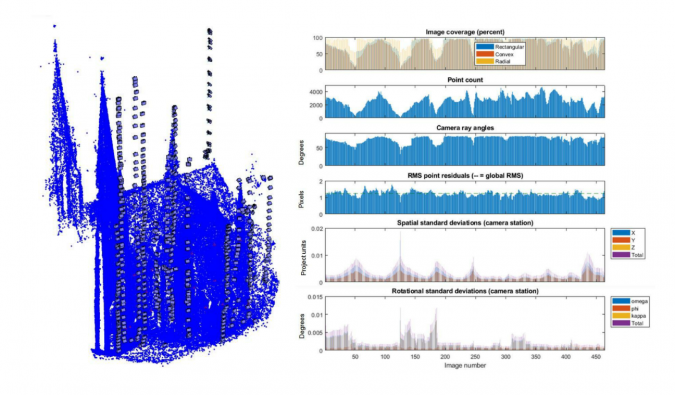
Hình 1: Xử lý đo quang trong DBAT (trái) và các chỉ số đã tạo (phải).
Kiểm soát chất lượng
Trước khi thực hiện các hoạt động trên chính đám mây điểm, cần phải kiểm soát chất lượng thích hợp. Khía cạnh này của tài liệu di sản 3D là rất cần thiết, nhưng trong thực tế thường bị lãng quên. Mặc dù các khía cạnh trực quan có thể làm say mê người dùng, nhưng độ chính xác hình học vẫn là một phần không thể thiếu của bất kỳ nỗ lực lưu trữ di sản nào. Thật vậy, các nhà khảo sát và kỹ sư địa tin học có nghĩa vụ duy trì chất lượng hình học của các sản phẩm không gian địa lý, và hơn thế nữa khi họ phải đảm bảo việc sử dụng các sản phẩm nói trên để lưu trữ di sản lâu dài.
Ví dụ, trong phép đo quang, sự gia tăng của cấu trúc từ chuyển động (SfM) và các thuật toán đối sánh dày đặc tạo ra kết quả ấn tượng về mặt hình ảnh. Tuy nhiên, bản chất hộp đen của phần mềm SfM có nghĩa là việc kiểm soát chất lượng khó thực hiện hơn. Để giải quyết vấn đề này, tác giả và nhóm của mình đã phát triển một giao thức để trích xuất các chỉ số chất lượng từ các dự án đo quang SfM bằng cách sử dụng hộp công cụ điều chỉnh gói giảm ẩm (DBAT) (xem Hình 1 để làm ví dụ). Sử dụng phương pháp mã nguồn mở này để đánh giá chất lượng đo quang cho phép các vấn đề trong dự án được xác định sớm và do đó được khắc phục trước khi lỗi lan rộng thêm. Trong số những thứ khác, DBAT cung cấp các số liệu đo quang học cổ điển thường bị thiếu trong phần mềm tái tạo 3D dựa trên hộp đen SfM hiện đại, ví dụ: ma trận hiệp phương sai định hướng bên ngoài, các góc giao nhau, v.v.
Phân chia đa tỷ lệ
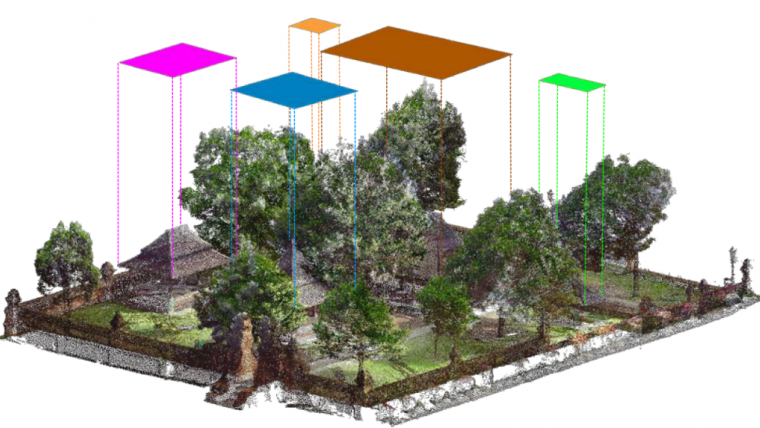
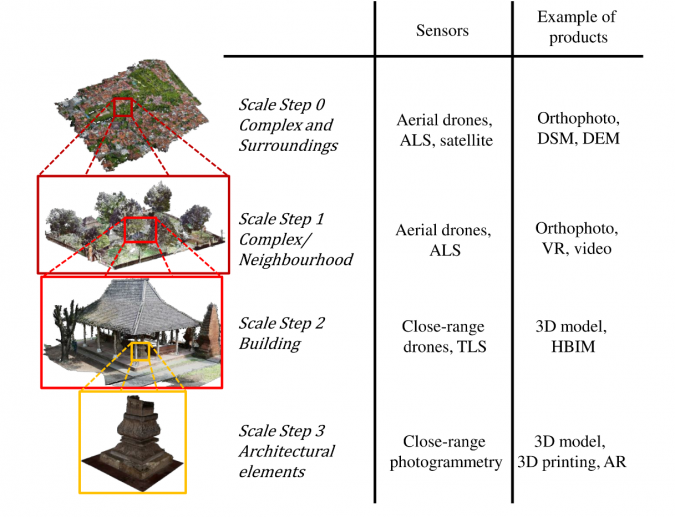
Sau khi chất lượng của dự án đã được đảm bảo, đám mây điểm kết quả có thể được điều khiển thêm. Bước đầu tiên trong phương pháp đã phát triển của tác giả là chia dữ liệu di sản 3D một cách có hệ thống thành nhiều bước theo tỷ lệ. Ví dụ: bước quy mô đầu tiên liên quan đến các khu vực rộng lớn xung quanh một địa điểm nhất định có thể được quét bằng máy bay không người lái (UAV hoặc 'máy bay không người lái'). Bước thứ hai sau đó có thể liên quan đến các tòa nhà đơn lẻ, có thể được tái tạo lại bằng cách quét laser trên mặt đất (TLS) hoặc phép đo quang. Sau đó, bước thứ ba có thể liên quan đến các phần chi tiết hơn của tòa nhà, tức là các yếu tố kiến trúc như cột trụ, tường, sàn nhà, v.v. Cách tiếp cận phân đoạn từ thô đến tinh này giúp các chức năng thuật toán tạo ra một hệ thống phân cấp có hệ thống về thông tin ngữ nghĩa, cũng như giảm đáng kể thời gian xử lý. Hình 2 minh họa sự phân chia đa tỷ lệ này trong một nghiên cứu điển hình được thực hiện trên quần thể cổ tích Kasepuhan thế kỷ 16 ở Cirebon, Indonesia.
Hình 2: Phân cấp đa tỷ lệ của tập dữ liệu di sản văn hóa.
Phương pháp đa tỷ lệ cũng cố gắng đáp ứng các cảm biến 3D khác nhau có sẵn ngày nay. Thật vậy, mỗi phương pháp có thể phù hợp với một mức quy mô nhất định nhưng không phù hợp với những phương pháp khác, vì vậy cấu trúc phân cấp của dữ liệu này cũng có thể hữu ích cho mục đích quản lý dữ liệu.
Phân đoạn và chú thích
Theo mô hình đa tỷ lệ đã được thiết lập trước đó, quá trình giải cấu trúc sau đó bắt đầu với việc phân đoạn các tòa nhà từ một đám mây điểm lớn hơn, tức là của khu phức hợp xung quanh. Điều này được thực hiện với sự trợ giúp của các tệp GIS 2D có sẵn từ trước. Các tệp GIS như vậy thường đã có sẵn cho các khu di sản, nhưng cũng có thể vector hóa nhanh dựa trên hình ảnh vệ tinh hoặc UAV nếu không có dữ liệu đó. Việc sử dụng GIS cũng thể hiện một ưu điểm khác: lớp ngữ nghĩa và thông tin được nhúng dưới dạng các thuộc tính trong các lớp và thực thể GIS. Do đó, thuật toán ‘cookie-cutter’ được phát triển thực hiện phân đoạn hình học bằng cách sử dụng các đa giác vectơ GIS làm hướng dẫn. Thuộc tính ngữ nghĩa được liên kết với mỗi thực thể đa giác sau đó có thể được chú thích tự động vào kết quả được phân đoạn. Hình 3 cho thấy kết quả của một hoạt động như vậy, theo đó vectơ GIS hoạt động như một khuôn 2,5D để phân đoạn đám mây điểm thô. Ghi nhãn tự động bằng cách sử dụng các thuộc tính GIS có nghĩa là các đám mây điểm xây dựng kết quả có thể truy vấn theo nghĩa cơ sở dữ liệu cơ bản.
Kết quả của việc phân đoạn này - từ khu phức hợp di sản đến các tòa nhà di sản - do đó bao gồm các tòa nhà riêng lẻ với thông tin ngữ nghĩa thu được từ tệp GIS gốc và dữ liệu hình học từ đám mây điểm gốc. Về vấn đề này, nó trình bày một ví dụ về phân đoạn thể hiện trái ngược với phân đoạn ngữ nghĩa tổng quát hơn. Về chất lượng phân đoạn, thuật toán của tác giả đã ghi được chỉ số F1 là 89,32% trên tập dữ liệu đã thử nghiệm bằng cách sử dụng phương pháp này.

Hình 3: Phân đoạn đám mây điểm theo kiểu ‘cookie-cutter’ và chú thích ngữ nghĩa.
Việc giải cấu trúc thêm liên quan đến việc tháo rời các tòa nhà (kết quả của bước trước) thành các yếu tố kiếntrúc. Các quy tắc hình học khác nhau đã được sử dụng trong quá trình này, không chỉ để thực hiện phân đoạn đơn giản mà còn để phân bổ các lớp cho mỗi cá thể. Tác giả và nhóm của ông đã phát triển một số chức năng để thực hiện việc phát hiện và phân loại hai yếu tố kiến trúc thường thấy trong dữ liệu di sản, ví dụ: trụ / cột và khung mái. Thuật toán phát hiện dựa trên một số thuật toán như RANSAC, Hough-Transform và phân đoạn lân cận gần nhất. Thuật toán phát hiện trụ cột đã được thử nghiệm trên năm bộ dữ liệu khác nhau với nhiều kiểu kiến trúc khác nhau và thực hiện thành công nhiệm vụ với điểm F1 trung bình là 88,97%. Nó cũng quản lý để xác định một cách chính xác số lượng 'trụ cột' (được định nghĩa là trụ đỡ của tòa nhà có mặt cắt ngang hình tròn, được hiển thị bằng màu đỏ trong cột 'phân loại' của Hình 4) trái ngược với 'cột không' (được hiển thị bằng màu xanh lam cột 'phân loại' của Hình 4).
.png)
Hình 4: Kết quả phân đoạn và phân loại các trụ cột trên năm tập dữ liệu đã thử nghiệm.4
Kết luận
Cách tiếp cận được mô tả trong bài viết này có mục tiêu cuối cùng là hỗ trợ quá trình phân đoạn và phân loại đám mây điểm trong bối cảnh tài liệu di sản văn hóa. Về vấn đề này, thuật toán được phát triển đã cho thấy kết quả đầy hứa hẹn với độ chính xác tốt đáng ngạc nhiên. Thật vậy, việc sử dụng loại phương pháp heuristic này có thể là đủ trong nhiều trường hợp đơn giản mà không cần phải sử dụng đến máy học. Hơn nữa, tác giả đề xuất một quy trình làm việc kỹ lưỡng với việc bao gồm đánh giá chất lượng hình học ở đầu quy trình. Tuy nhiên, hiệu quả của thuật toán có thể gặp nhiều hạn chế hơn khi xử lý tập dữ liệu đa dạng hơn, đây là trường hợp trong miền di sản văn hóa. Do đó, cũng rất thú vị khi khám phá việc sử dụng loại phương pháp tiếp cận thuật toán này để phân đoạn đám mây điểm trong việc tạo tập dữ liệu đào tạo sẽ hữu ích để hỗ trợ các phương pháp tiếp cận dựa trên trí tuệ nhân tạo trong tương lai.